NSF-REU Program 2021 at UMBC
Professional Development Activities
Invited Talks from UMBC Leaders
Invited Talks from External Research Lab and Graduate School
External Activities
Weekly Individual Research Meeting and Training
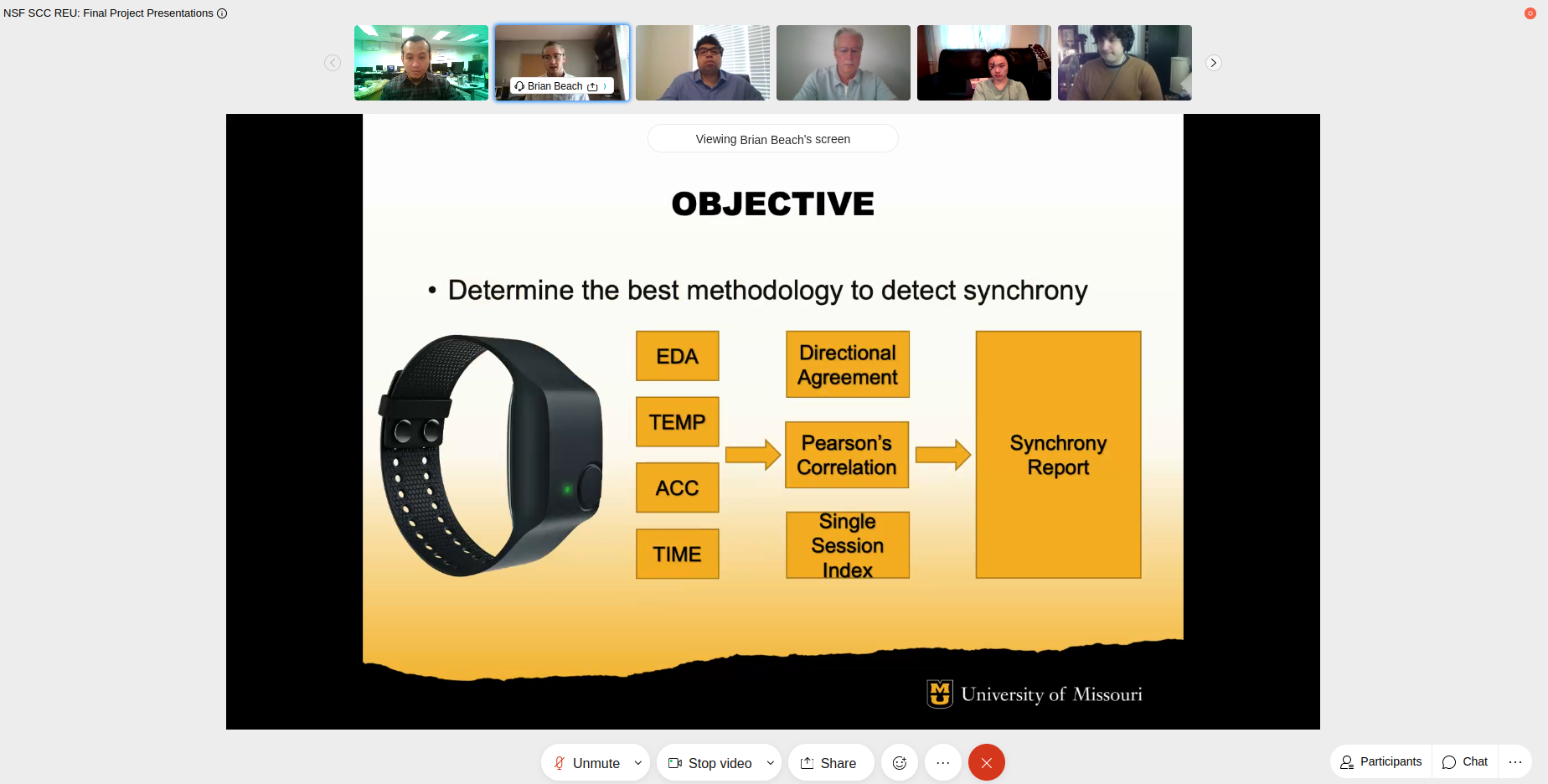
Determining the effect of physiological synchrony of mental states and performance during in-situ training
REU student: Brian Beach
Mentors: Dr. Andrea Kleinsmith
Abstract—The goal of this research project is to understand the effect that physiological synchrony has on a group’s stress, mental load, and performance in high stakes situations. Physiological synchrony is the linking of subconscious physiological responses between humans and has previously been studied at the dyadic social interaction level. This project extends it to higher stakes situations and can be used as the foundation for future research of physiological synchrony in larger groups or more stressful situations. The project uses in-house physiological data gathered via Empatica E4 bands from medical trainee dyads during in-situ training. The data includes the trainee’s heart rate, temperature, movement, and electrodermal activity (EDA). At the end of training sessions, the trainees completed a survey on their mental states on the criteria of their stress, anxiety, and mental effort. The trained paramedic instructors who oversaw the trainees filled out a survey on the trainees’ performance on the criteria of patient care, crew interaction, and timing. To analyze the data a system was created to produce a full report based on the raw E4 data sets of two trainees and the completed surveys. The E4 data is segmented by time to cover just the period of training, then cleaned, smoothed, and normalized. To model the synchrony of the two E4 data sets an analysis of Pearson’s Correlation and Directional Agreement is applied. A machine learning model was then applied to the synchrony model to determine the effects that synchrony had on the trainees’ mental state and performance. Early analysis suggests that synchrony is linked to both stress and performance. We note that higher synchrony rates are correlated to lower stress and higher performance rates. In the future, we plan to evaluate the machine learning model in different contexts which may provide deeper insights in our analysis.
SpecTextor: dense automated text generator for sports news article
REU student: Matthew Ivler
Mentors: Indrajit Ghosh, Sreenivasan Ramasamy Ramamurthy, Dr. Nirmalya Roy
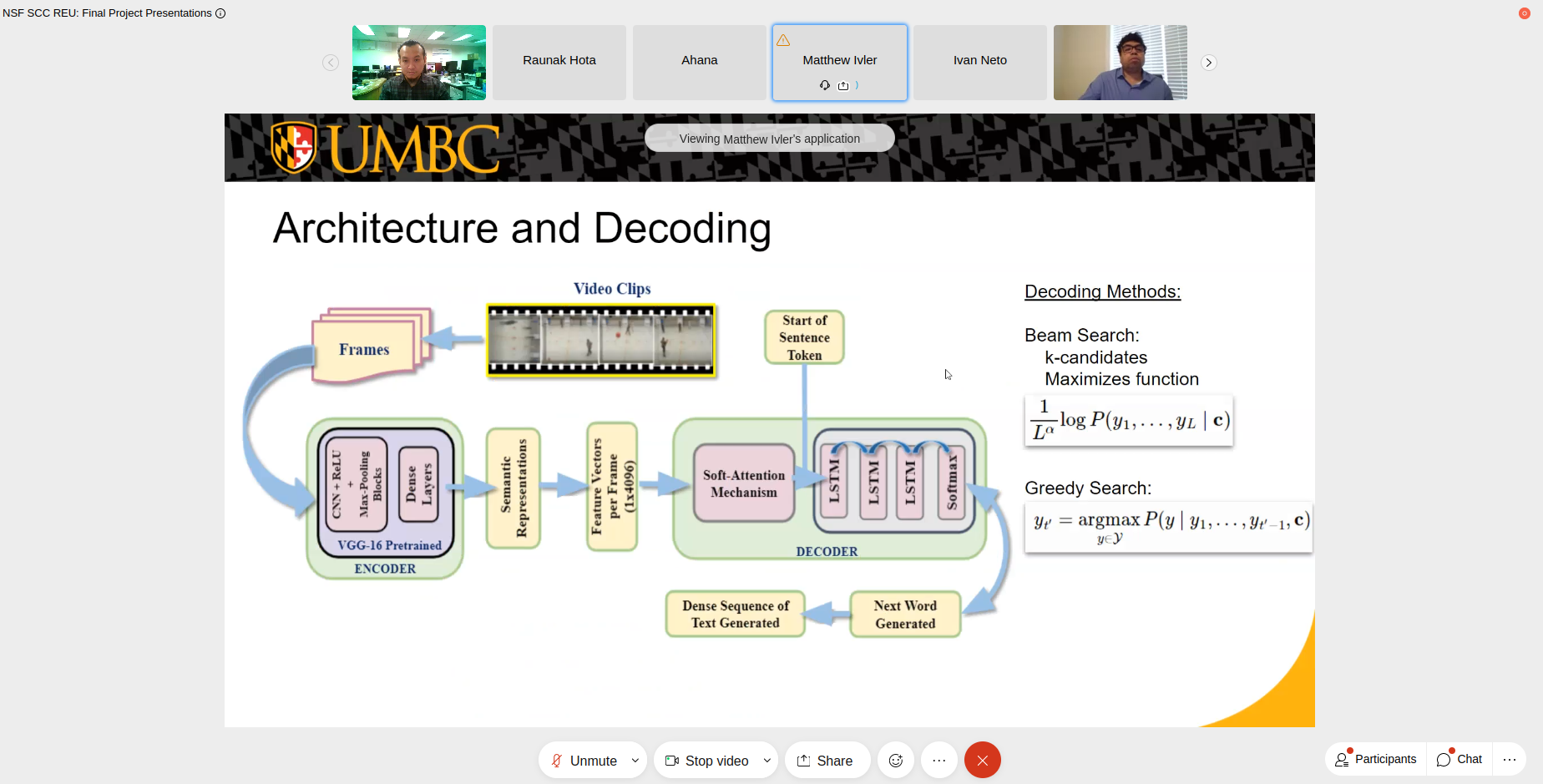
Abstract—A dense text generator learns the semantic knowledge and visual features of each frame of a video and maps them to describe the video’s most relevant subjects and events. Although dense text generation has been widely explored for untrimmed videos to generate associated texts across various domains, generating dense captions in the sports domain to supplement journalistic works without relying on commentators and experts still needs much investigation. This paper proposes an end-to-end automated text-generator that learns the semantic features from untrimmed videos of sports games and generates associated descriptive texts. The proposed approach considers the video as a sequence of frames and uses a sequential generation of words to develop detailed textual descriptions. After splitting videos into frames, we use a pre-trained VGG-16 model for feature extraction and encoding the video frames. With these encoded frames, we posit an LSTM based attention-decoder architecture that leverages soft-attention mechanisms to map the semantic features with relevant textual descriptions to generate the explanation of the game. Because developing a comprehensive description of the game warrants training on a set of dense time- stamped captions, we leverage the ActivityNet Captions dataset. In addition, we evaluate the proposed framework on both the ActivityNet Captions dataset and the Microsoft Video Description Dataset (MSVD), a dataset of shorter generalized video-caption pairs, to showcase the generalizability and scalability and also utilized beam search and greedy search for the evaluation of the SpecTextor. Empirical results indicate that SpecTextor achieves BLEU score of 0.64330 and METEOR score of 0.29768.
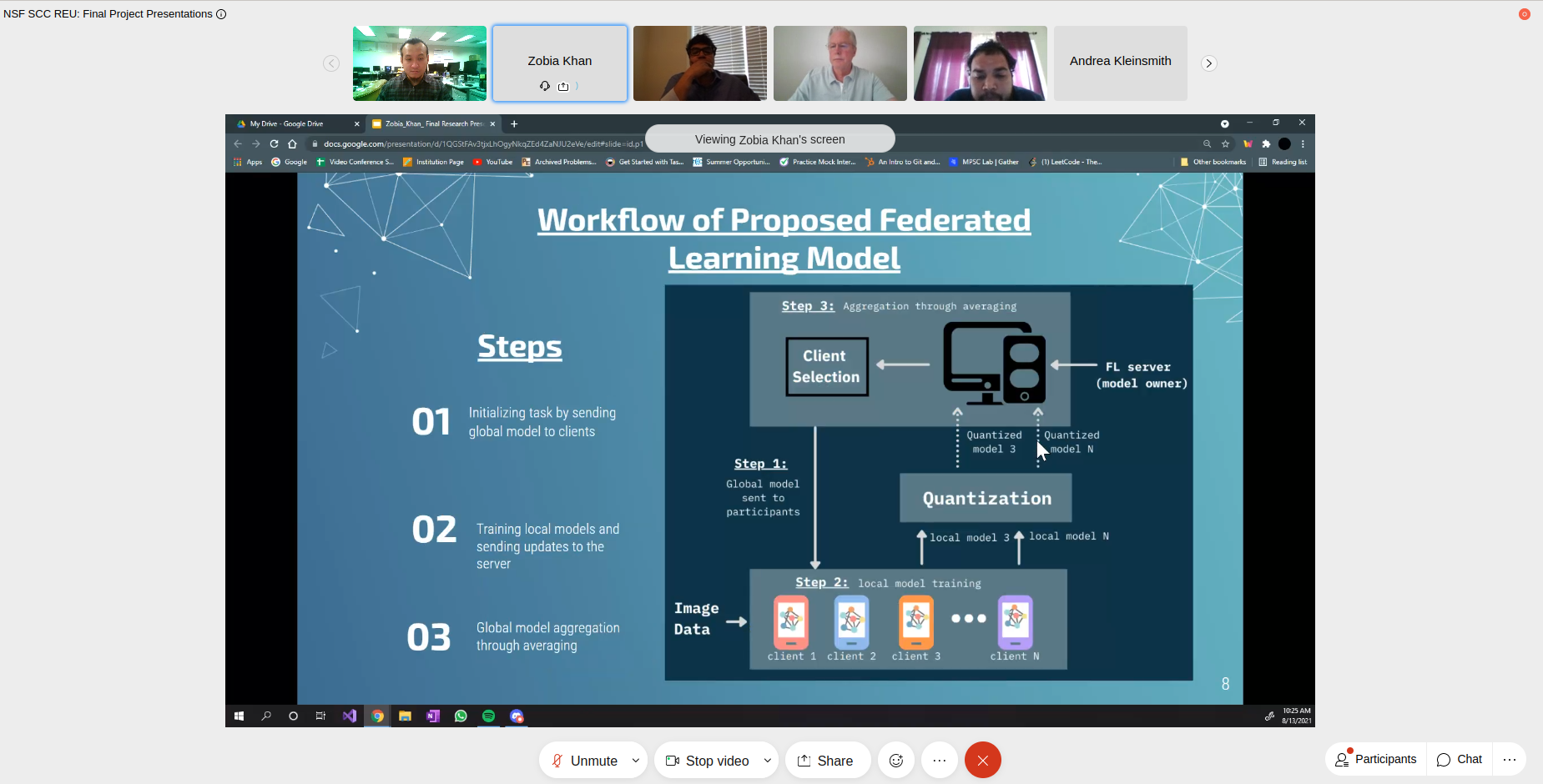
Resource efficient quantized federated learning model for brain tumor segmentation
REU student: Zobia Khan
Mentors: Emon Dey, Dr. Nirmalya Roy
Abstract—The proliferation of smart computing devices paves the way of applying artificial intelligence in almost all sectors of digital civilization but raises issues like personal data breaches. Preserving privacy of the data has become a crucial aspect especially in the medical domain, where sensitive information about the patients and even the institutions should be kept confidential. Federated learning is being investigated as a promising solution to this challenge but has some drawbacks itself. One of them is the issue of higher communication and computation cost when the model becomes large and complex because the model must be sent back and forth between server and clients while training. The combination of model compression techniques with federated learning algorithms can be a viable approach to subdue this problem. Considering this research scope, in this work, we present a resource-efficient federated learning scheme implemented considering medical domain application. We have chosen the 'Brain Tumor Segmentation (BraTS)' dataset published in 2020 for our experiments because of its comprehensiveness, and its well-suited for our motivation. We utilize U-net as our base deep model and develop a ternary quantized version of it to reduce computation complexity. We also present a benchmark study while running our proposed model at the client-side based on required power, memory, and inference time as a measurement of computation efficiency.
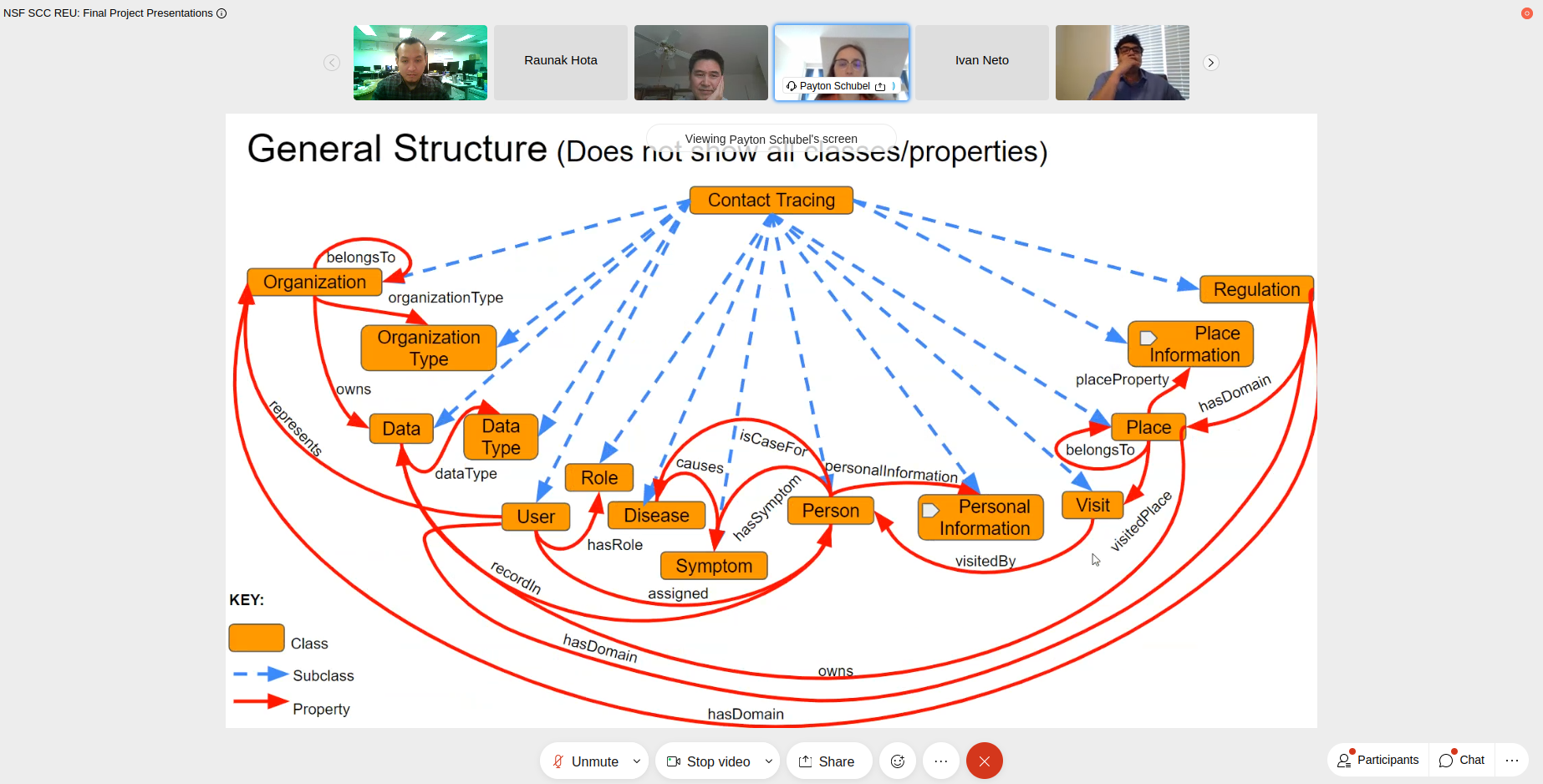
A Situation-Aware Access Control Framework for Contact Tracing
REU student: Payton Schubel
Mentors: Dr. Zhiyuan Chen
Abstract—The rapid evolution of the COVID-19 pandemic has shown that the ability to identify and control the spread of infectious disease is an essential part of public health infrastructure. One of the primary methods of controlling the spread of highly infectious diseases is contact tracing. Contact tracing is the process of identifying who an infected individual may have exposed while contagious. Manual contact tracing is often conducted through interviews with infected individuals, their contacts, and the places the infected individual has visited, but this can be slow and logistically challenging. App-based contact tracing often identifies contacts using either the location data or Bluetooth proximity data, but this has been shown to have substantial privacy and security concerns and is ineffective for individuals without the app. Effective contact tracing requires efficiency, clear communication, flexibility, and a level of trust that allows for the rapid exchange of data between all parties. To this end we propose a novel contact tracing ontology to facilitate situation-aware access control and automation of parts of the contact tracing process using semantic web technologies. The ontology is designed to allow the implementation of situation-aware access control using query rewriting to allow authorized system users to query an institution’s relevant data directly to ensure efficiency while maintaining security. Additionally, queries built leveraging semantic web technologies would allow automation of parts of the contact tracing process, including but not limited to identifying contacts, prioritizing investigations, and delegating responsibilities among available contact tracers and case investigators. Development of this ontology required carefully considering the existing contact tracing process, ontology structure and functionality, and potential access control and automation rules.
Multimodal Deep Learning for Medical Data Representations
REU student: Matthew Lee
Mentors: Dr. Sanjay Purushotham
Abstract—Cancer is the second leading cause of death in the United States. Within this category, head and neck cancers comprise approximately 4% of malignancies annually. Although the statistic may seem somewhat insignificant, it has only a 32% 5-year survival rate for brain tumors. For treatments pertaining to tumors in the brain, there is limited room for error which ultimately presents the challenge of accurately identifying where exactly the tumor exists. Thus, recent work has explored the use of medical imaging such as Positron Emission Tomography (PET) and Computed Tomography (CT) scans for non-invasive detection of brain tumors. The goal of this research project is to segment the location of the head and neck tumors in the PET and CT scans by developing deep learning based semantic segmentation methods. Recent segmentation approaches are designed to work with one modality while our goal is to use both PET and CT scans for accurate tumor image segmentation. We are conducting our experiments on a dataset provided by the MICCAI HECKTOR 2021 challenge which consists of CT, PET scans, clinical data for 224 patients across 5 different centers. Our exploratory data analysis on this dataset has shown that slice and data distribution varies across centers. Empirical results by using Otsu’s algorithm, a threshold based segmentation approach, on CT scan segmentation achieves a Dice Similarity Coefficient (DSC) score of 0.20. We are now developing 2D and 3D UNet based deep learning models for achieving accurate segmentation from both CT and PET scan images. We are also building a Docker image pipeline for end-to-end training and testing of various segmentation models. The semantic segmentation results of this project will be used for prediction of progression free survival time.
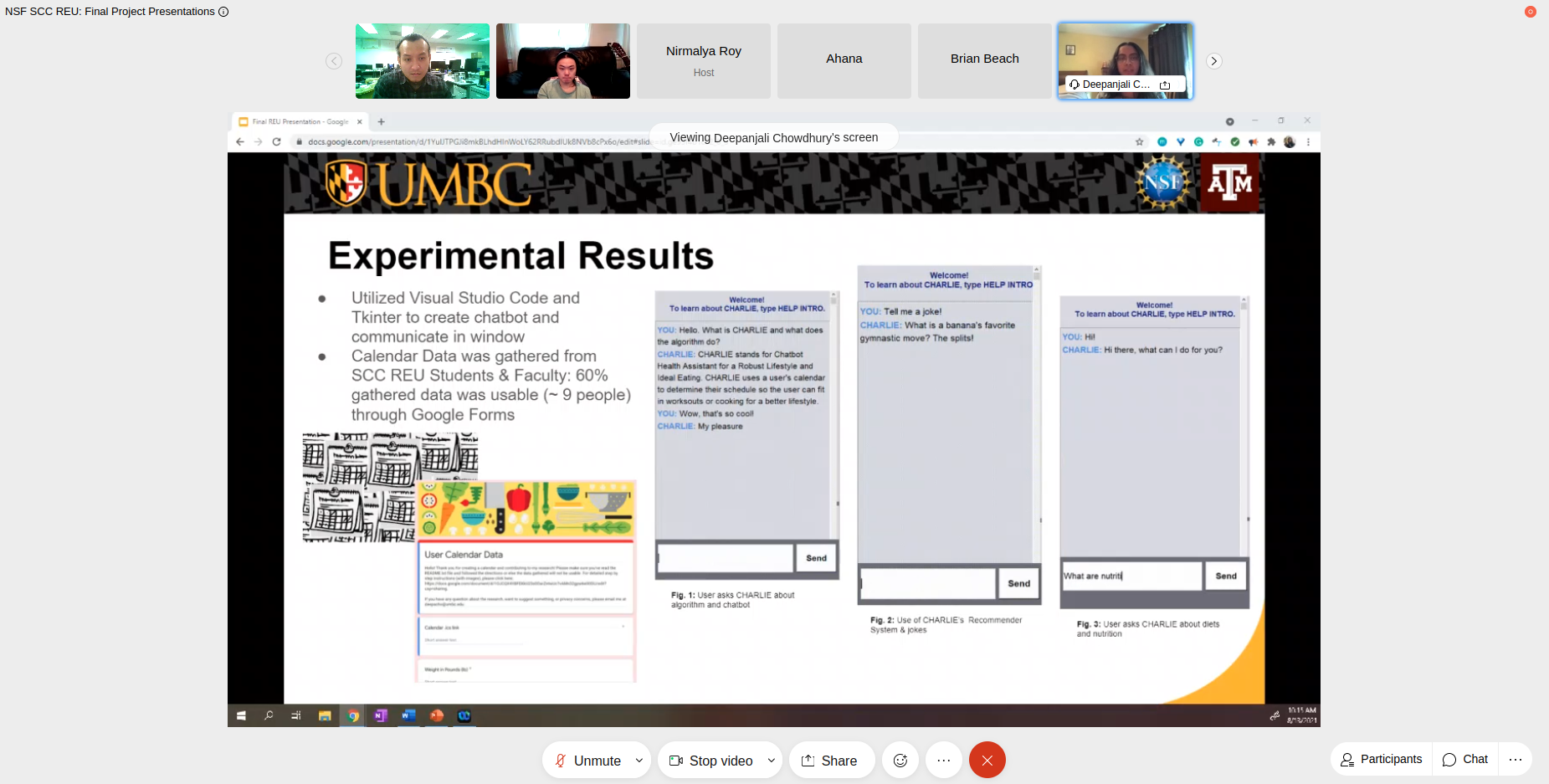
CHARLIE: A Chatbot that Recommends Daily Fitness and Diet Plansn
REU student: Deepanjali Chowdhury
Mentors: Sreenivasan Ramasamy Ramamurthy, Dr. Nirmalya Roy
Abstract—Managing a work-life balance has always been challenging especially after the recent trend of working from home, which has made maintaining one’s fitness and diet regime strenuous. Failing to adhere to a fitness and diet plan has shown to cause long-term effects on a person’s health including obesity and shortened lifespans. Currently, people plan their fitness and diet plans around their schedule, however, it is very challenging to keep up with and users tend to give up these plans due to lack of time and planning. To help with better planning for a fitness and diet regime, we propose “CHARLIE”, a chatbot that works around a user’s schedule to intelligently recommend diets and fitness goals based on their calendar. The chatbot will use a recommender system that will suggest the user certain meals and fitness activities based on the amount of time they have left in their day and the number of calories they lose.
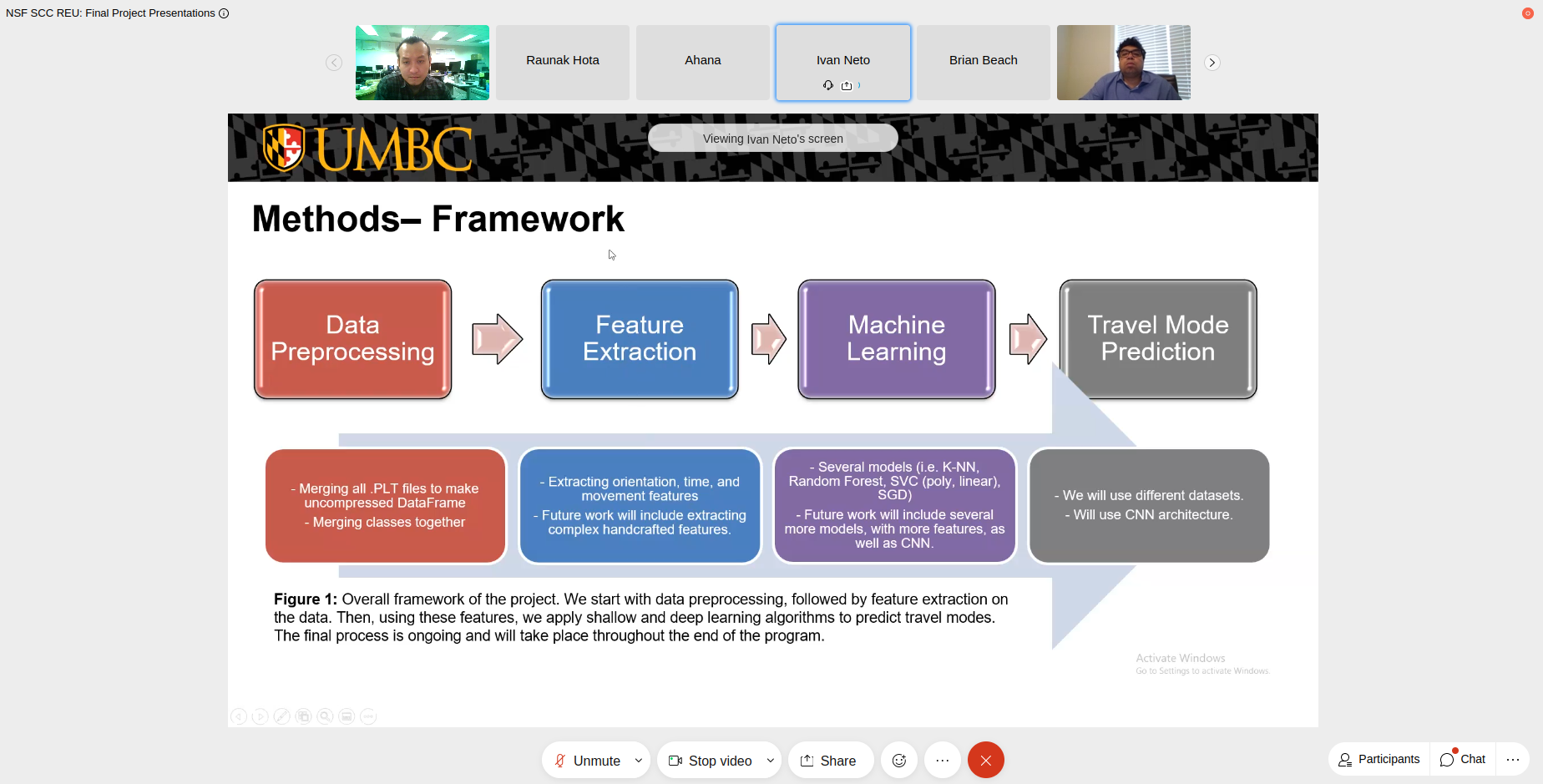
Unseen travel mode detection using transfer learning
REU student: Ivan Neto
Mentors: Naima Khan, Dr. Nirmalya Roy
Abstract—Travel mode detection has been targeted in few literatures in the past. Several geometrical and machine learning based algorithms have been designed to detect the mode of transportation. However, existing models require significant amounts of labeled trajectory data. of different transportation modes. From the perspective of transportation, some trajectory features can be similar for a set of transportation modes while it differs from other types of transportation modes. For example, the rate of changing direction for walking and biking is not as straightforward as for car, bus, or taxi. According to our study in this area, there is not much research found exploring the use of transfer learning in this regard. In this project, we are experimenting on the feasibility of using pretrained models on GPS trajectory data to predict unseen transportation modes of trajectories collected from smartphone GPS applications. We use Microsoft Geolife dataset, and we focus on a subset of the data which comprises 73 users with labeled data. We also collected trajectory data from different locations using a smartphone application named ‘Strava’ which provides similar data variables as of Geo-life dataset, but with different frequency. We incorporated all the features mentioned in the previous literature and tested several shallow learning algorithms (i.e. Random Forest, SVM, Decision Tree) on the labeled geo-life dataset where Random Forest (96.9% accuracy) outperforms other algorithms. We also implemented a supervised CNN-based network to detect the transportation modes. We plan to use initial layers of the model to extract general features from our collected dataset with strava and detect the unseen travel modes (i.e. segway) that are not present in the geo-life dataset.
Respiratory Symptoms Detection and Domain Adaptation Feasibility Using Earables
REU student: Nhan Nguyen
Mentors: Avijoy Chakma, Dr. Nirmalya Roy
Abstract—The COVID-19 pandemic has brought a devastating effect on human health across the globe. People are still observing face masking in public places to contain the spread of COVID-19 as coughing is one of the primary transmission mediums. Early cough detection with identifying the fine-grained contextual information plays a significant role in preventing COVID-19 spread among the close-by cohorts. Many approaches proposed for developing systems to detect cough in literature, but earable devices are inadequately studied for respiratory symptom detection. In this work, we leveraged an acoustic research prototype-eSense that embeds acoustic and IMU sensors into user-convenient earbuds to find out answers for the two following questions – 1. How feasible is it for the earables to detect respiratory symptoms? and 2. How scaleable are the developed models when exposed to unseen dataset samples? In our study, we have experimented with traditional machine learning models and a deep learning model. We found that thedeep learning model outperforms the conventional algorithms on a large scale, achieving 97.51% accuracy. We further investigated the model scaleability for the unseen datasets. We found that the model performance drops sharply when a model is trained on a particular dataset and tested on an unseen dataset. To mitigate such issues, we explored using an adversarial domain adaptation technique.
Drone-VQA: Visual Question Answering for Drone Images
REU student: Raunak Hota
Mentors: Dr. Maryam Rahnemoonfar
Abstract—In the wake of the recent Surfside condominium collapse and deadly flooding in Western Europe in addition to the growing threat of natural disasters from climate change, the need for post-disaster analysis tools has been exemplified. Unmanned aerial vehicles (UAVs) have the ability to safely survey the aftermath of disasters and when combined with Visual Question Answering systems can return real-time answers to image-related questions that can assist in cleanup and analysis. The creation of such a VQA system requires training a neural network on images of disaster aftermath.The VQA model is made accessible to test via a published site. Users can enter any questions and either select from a sample of existing disaster photos or upload their own which the model will evaluate and output the most likely responses.
Multi-domain Vulnerability Assessment
REU student: Mishelle Harnandez
Mentors: Dr. Vandena Janeja, Mohammad Alodadi
Abstract—The development of the network of systems and applications brings many advantages to the world but also carries risk. One of the biggest risks is the presence of vulnerabilities in software and hardware components due to an application weakness, which could be a design defect or an implementation error. This opens a window to third parties that could take advantage of this weakness and attack the system’s core functionalities and often cause irreversible damage. Due to the presence of many vulnerabilities, it is often hard to process them manually and also identify potential relationships between vulnerabilities. To address this problem, we propose an approach that has the ability to process thousands of vulnerabilities from different reporting platforms through an artificial intelligence pipeline to associate and connect them.